생성적 적대 신경망(Generative Aversarial Network, GAN)
GAN의 가장 주요한 목적은 훈련 데이터셋과 동일한 분포를 가진 새로운 데이터를 합성하는 것이다.
GAN의 원본형태는 레이블 데이터가 필요하지 않기 때문에 비지도 학습으로 분류된다.
원본 GAN을 확장한 것은 비지도, 지도 학습 양쪽 모두 해당한다.
GAN을 이용하면, 컴퓨터 비전에서
이미지-투-이미지 변환(image-to-imae translation)(입력 이미지에서 출력 이미지로 매핑하는 방법)
이미지 초해상도(image super-resolution)(낮은 해상도의 이미지를 높은 해상도의 이미지로 변환)
이미지 인페이팅(image inpainting)(이미지에서 누락된 부분을 재구성하는 방법을 학습) 등
다양한 애플리케이션에서 사용가능하다.
https://www.thispersondoesnotexist.com
GAN을 통해 생성한 고해상도 얼굴 이미지
오토인코더(auto encoder)
기본 오토인코더는 이미지를 생성할 수는 없지만, 훈련 데이터를 압축하고 해제할 수 있다.
오토인코더는 인코더(encoder) 신경망과 디코더(decoder) 신경망으로 구성되어 있다.
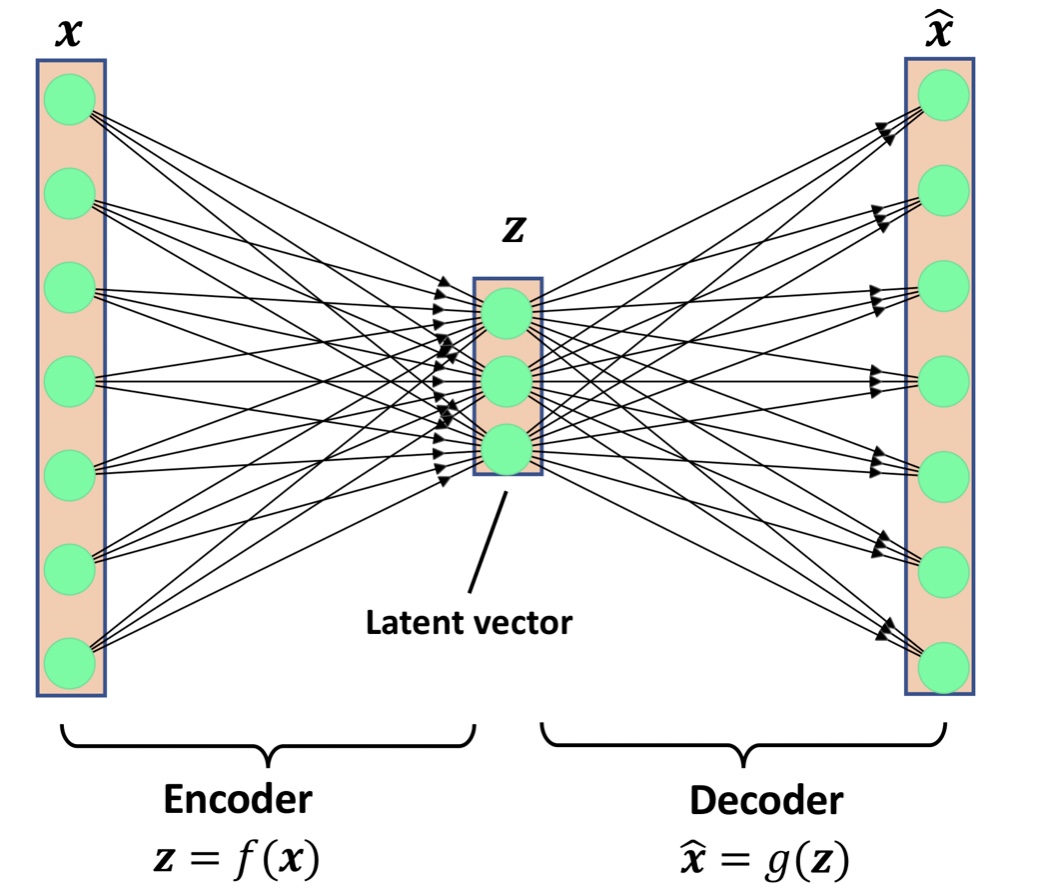
d차원 입력 특성 벡터 x는 인코딩 신경망에서 p차원 벡터 z로 인코딩된다.(p<d)
(z는 잠재벡터(latent vector) 또는 잠재 특성 표현이라고 부른다.)
p차원 잠재 벡터 z는 디코딩 신경망을 통해서 압축을 해제할 수 있다.
PCA(주성분 분석), LDA(선형 판별 분석)의 차원 축소 기법처럼 오토인코더도 차원 축소 기법으로 사용 가능하다.
(오토인코더 인코더와 디코더에서 비선형성이 없다면, PCA와 거의 동일하다.)
위의 오토인코더는 인코더 신경망과 디코더 신경망 사이에 은닉층이 없지만,
사이의 복잡한 은닉층을 추가해서 심층 오토인코더를 만들 수 있다.
(더욱 효과적인 데이터 압축과 재구성 함수를 학습할 수 있다.)
참고) 과대완전(overcomplete) 오토인코더
오토인코더의 잠재공간(latent space)의 차원은 일반적으로 입력층 차원보다 더 작다.(p<d)
위와 같이 차원 축소의 용도로 사용 가능한 오토인코더를 과소와전(undercomplete)라고 한다.
잡음 제거 오토인코더(denoising autoencoder)
반대로 과대완전(overcomplete)는 잠재 벡터 z의 차원이 입력 샘플의 차원보다 더 크다.(p>d)
과대완전에서 단순히 입력 트성을 출력층에서 그대로 복사할 수 있기 때문에
훈련과정을 조금 수정하여 과대완전 오토인코더를 잡음감소(noise reduction)용도로 사용가능하다.
(잡음이 있는 데이터를 통해서 잡음이 없는 깨끗한 샘플로 재구성하는 방법을 학습)
새로운 데이터 합성(생성 모델)
오터인코더가 훈련되고 나면 입력 x에 대해 저차우너 공간의 압축된 버전에서 이 입력을 재구성할 수 있다.
압축된 표현을 변환하는 식으로 입력을 재구성하는 것을 넘어서 새로운 데이터를 생성할 수 없다.
생성 모델은 랜덤한 벡터 z를 새로운 샘플로 생성할 수 있다.

z는 완벽하게 특징을 알고있는 간단한 분포에서 만들어지기 때문에 쉽게 샘플링할 수 있다.
(ex z~Uniform(-1, 1) or z~Normal(m=0, sig^2=1))
오토인코더 & 생성모델
오터인코더와 생성모델은 둘 다 잠재 벡터 z를 입력으로 받고 x와 동일한 공간에 있는 출력을 만든다는 점에서 유사하다.
하지만 오토인코더에 있는 z의 분포를 알 수 없지만, 생성 모델에서는 z의 분포를 완벽하게 알고 있다.
오토인코더를 생성모델로 일반화할 수 있다. VAE도 그 중 한 방법이다.
VAE
VAE에서는 입력 샘플 x를 받으면, 인코더 신경망이 잠재 벡터 분포의 두 요소 평균과 부난을 계산한다.
VAE에서는 입력 샘플 x를 받으면, 인코더 신경망이 잠재 벡터 분포의 두 요소 평균과 부난을 계산한다.
VAE는 훈련하는 동안 표준 정규 분포에 평균과 분산이 맞도록 조정한다.
훈련 이후, 디코더 신경망을 이용해서 가우시안 분포에서 랜덤하게 샘플링한 z 벡터를 주입해서 새로운 샘플을 생성한다.
VAE, 자기회귀모델(autoregressive model), 노멀라이징 플로 모델(normalizing flow model), GAN과 같은
다양한 생성 모델이 존재한다.